
Observable Framework Is Core to My Process
One of the first projects I got excited about was Webby — a small Ruby gem that generated a static site from markdown. Before the JAMstack ‘revolution’, static sites were a niche, but one that existed for sure. Jekyll won that early market.1 Long before NPM supply chain attacks were on anyone’s radar, I loved the idea of simple websites with limited upkeep. Yesterday I shipped search for this blog (built on Hugo) powered by a precompiled index. Simple, beautiful, future proof.
As I start blogging more regularly again, I expect I’ll keep coming back to the core tooling and base tech that drive my process. Observable Framework is one of those tools. Admittedly, it’s a terrible name — terrible to search for — but worth bookmarking.
Observable is co-founded by Mike Bostock, the creator of D3.js. What I’ve found useful is that Framework is an easy aggregator of data with a simpler execution model than Jupyter, in my estimation.
Critically for me, it ships with a powerful DuckDB WASM client as part of the central workflow, which makes it very useful for data exploration and analysis. A few examples I’ve built with it recently:
- An analysis of XC ski competitors
- S3 bucket analysis — object versions, lifecycle cost modeling, and other storage optimizations.
- Structured log analysis of AWS CloudTrail logs as a precursor to building data pipelines on top of structured log information — including tracing spans built around structured logs instead of trace data.
- An impact analysis at my current client, combining code contributions with other data sources to provide a view of the value my work delivered to the business.
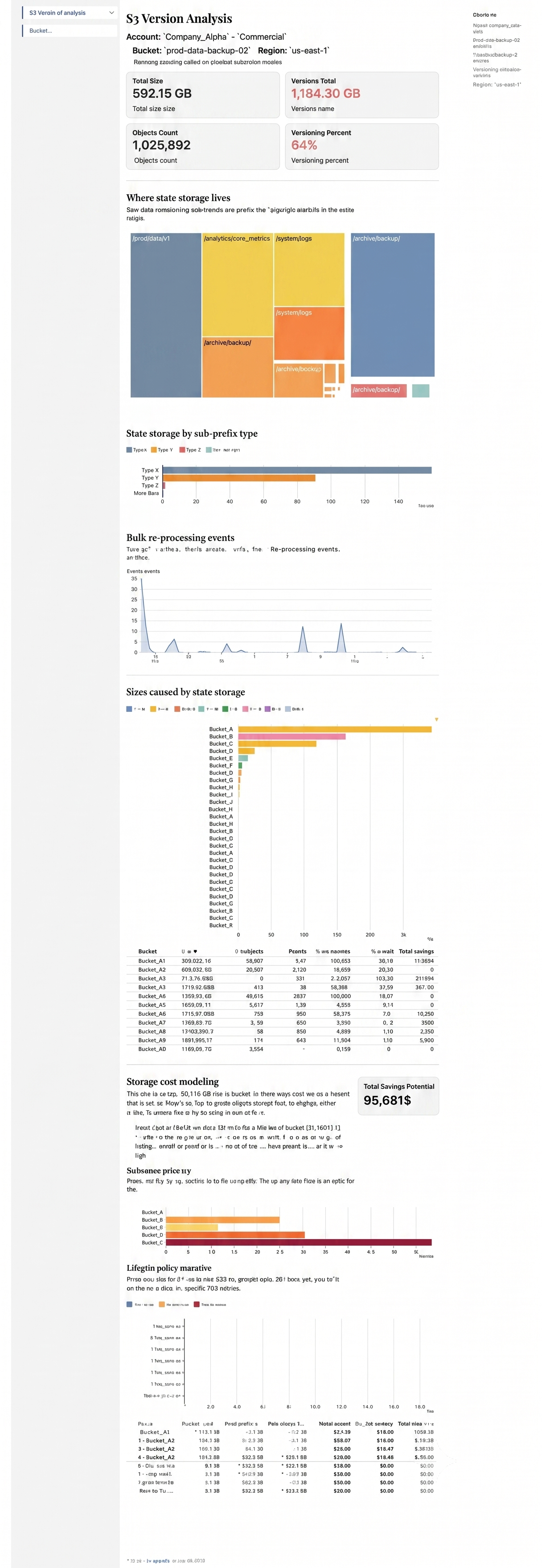
Yes, the labels above read like “S3 Veroin of analysis” and “Rannong azoding called on çloelbat subzroion moales” — turns out image models still can’t spell their way out of a bucket, but you get the idea. Framework makes it cheap to point DuckDB at an inventory export, iterate on the treemap and cost model in the same file, and hand the stakeholder a static page instead of a notebook they can’t run.
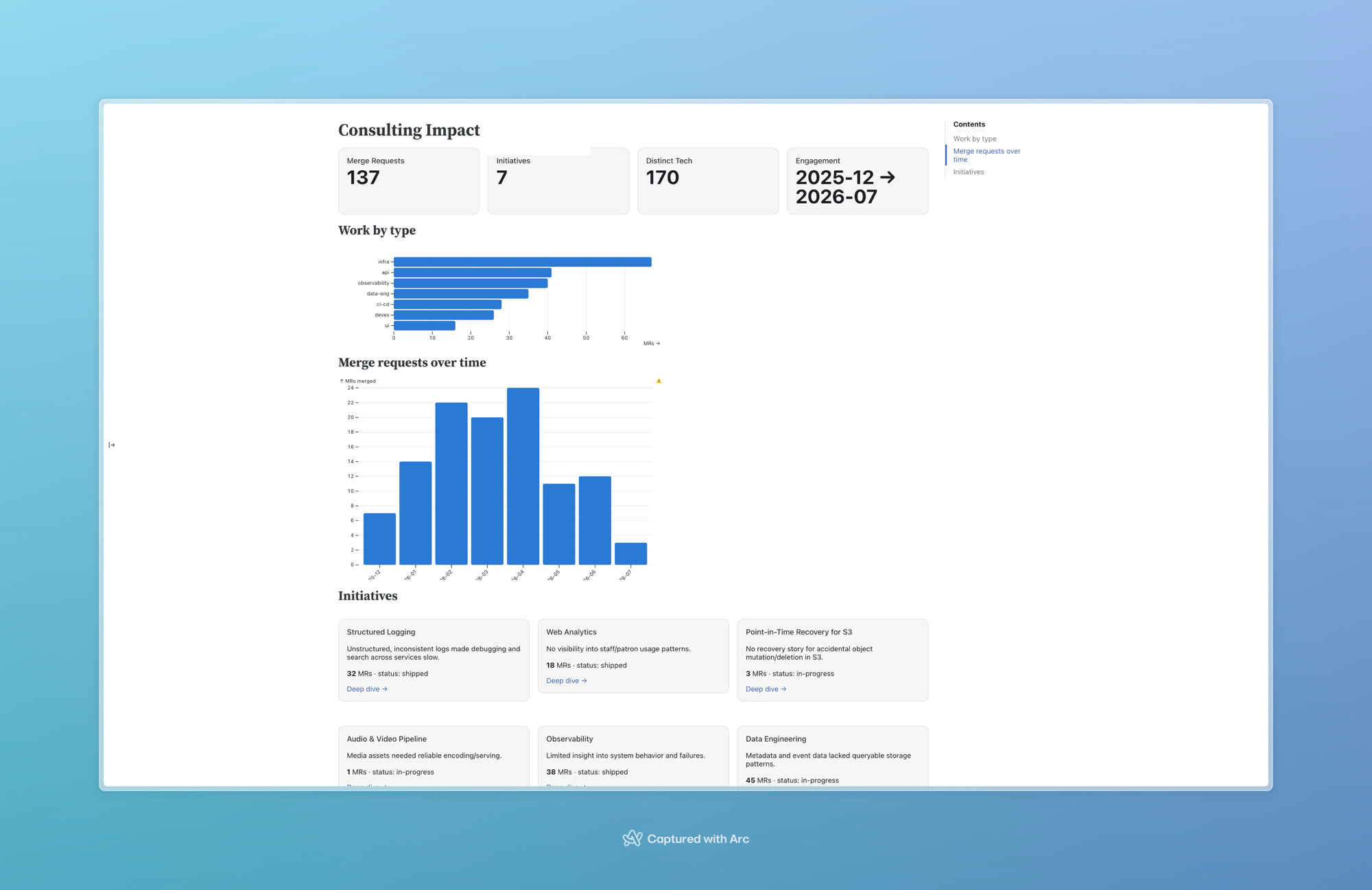
The impact dashboard is the same shape: point Framework at merged-MR history and initiative metadata, let DuckDB do the aggregation, ship a page that becomes a point of conversation, with dynamic data to support the conversation.
In each of these cases, Claude did most of the heavy lifting. For whatever reason the Observable Framework workflow seems reasonably LLM-friendly and consistent in its results.
I count this tech as part of my secret sauce. If you’re looking to learn more, reach out and get in touch.
If you’re evaluating Jekyll today, consider Bridgetown instead — a modern Ruby-powered successor with a healthier build story. ↩︎